Overview
![]()
![]()
Datasets come in all shapes and sizes, and are often messy:
Observations come in different formats
There are missing values
Labels are missing and/or aren’t consistent
Datasets need to be wrangled 🐄 🐑 🚜
The main goal of data-wrangler is to turn messy data into clean(er) data, defined as either a DataFrame or a
list of DataFrame objects. The package provides code for easily wrangling data from a variety of formats into
DataFrame objects, manipulating DataFrame objects in useful ways (that can be tricky to implement, but that
apply to many analysis scenarios), and decorating Python functions to make them more flexible and/or easier to write.
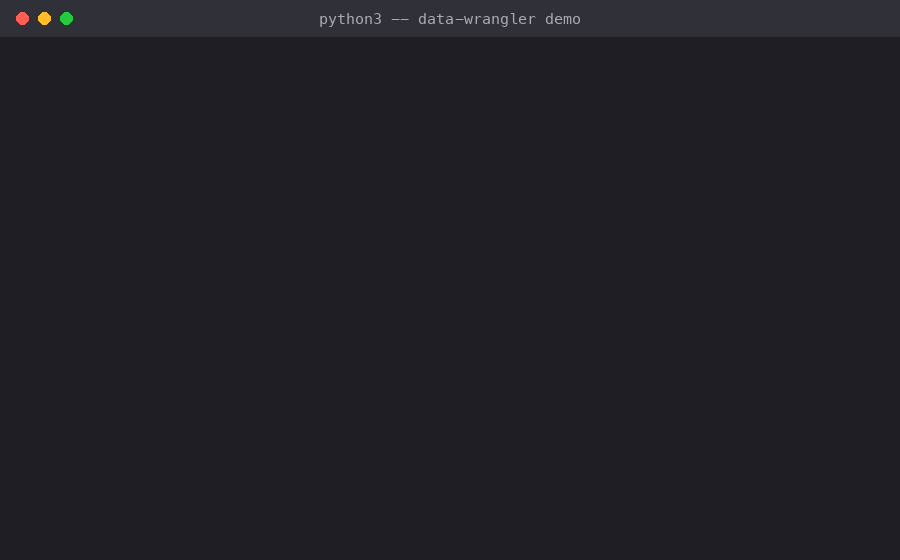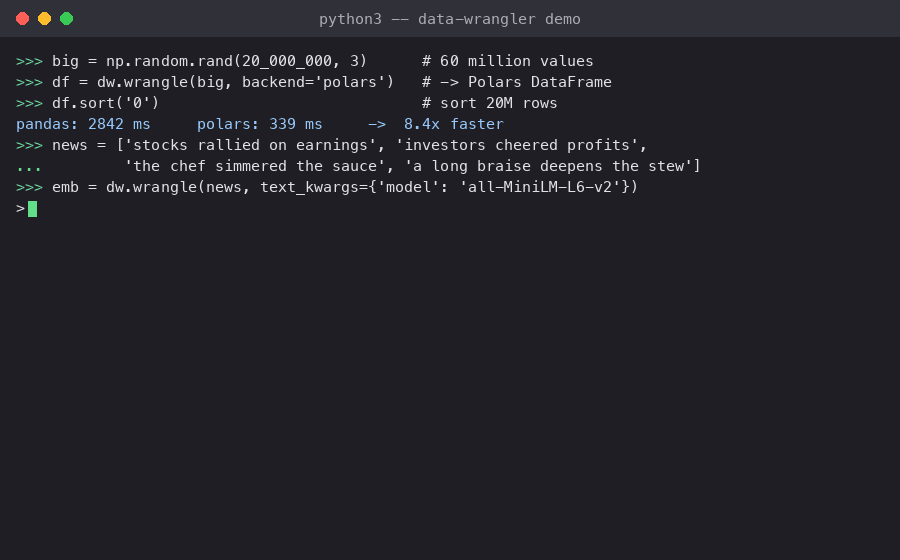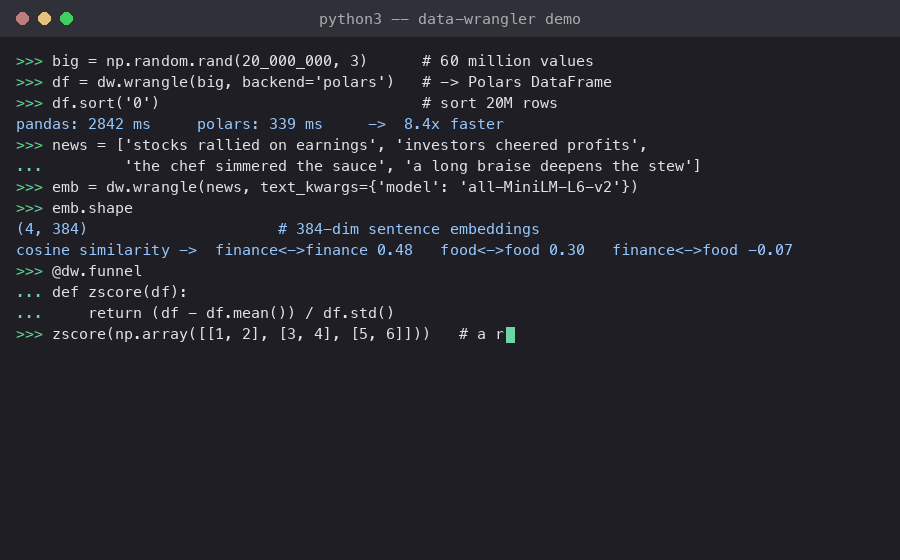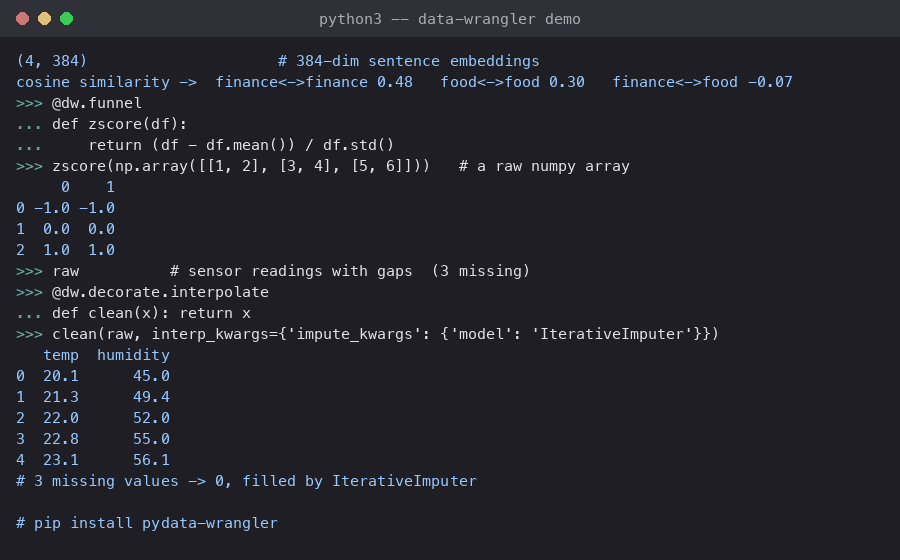
🚀 New: data-wrangler now supports high-performance Polars DataFrames alongside pandas, delivering 2-100x speedups
for large datasets with zero code changes. Simply add backend='polars' to any operation!
The data-wrangler package supports a variety of datatypes. There is a special emphasis on text data, whereby
data-wrangler provides a simple API for interacting with natural language processing tools and datasets provided by
scikit-learn and hugging-face (via sentence-transformers). The package is designed to provide sensible defaults, but also
implements convenient ways of deeply customizing how different datatypes are wrangled.
For more information, including a formal API and tutorials, check out https://data-wrangler.readthedocs.io
Quick start
Install datawrangler using:
$ pip install pydata-wrangler
Some quick natural language processing examples:
import datawrangler as dw
# load in sample text
text_url = 'https://raw.githubusercontent.com/ContextLab/data-wrangler/main/tests/resources/home_on_the_range.txt'
text = dw.io.load(text_url)
# embed text using scikit-learn's implementation of Latent Dirichlet Allocation, trained on a curated subset of
# Wikipedia, called the 'minipedia' corpus. Return the fitted model so that it can be applied to new text.
# NEW: Simplified API - just pass model names as strings or lists!
lda_embeddings, lda_fit = dw.wrangle(text, text_kwargs={'model': ['CountVectorizer', 'LatentDirichletAllocation'], 'corpus': 'minipedia'}, return_model=True)
# apply the minipedia-trained LDA model to new text
new_text = 'how much wood could a wood chuck chuck if a wood chuck could check wood?'
new_embeddings = dw.wrangle(new_text, text_kwargs={'model': lda_fit})
# embed text using sentence-transformers pre-trained model
# NEW: Simplified API - just pass the model name as a string!
sentence_embeddings = dw.wrangle(text, text_kwargs={'model': 'all-mpnet-base-v2'})
High-performance Polars backend examples:
import numpy as np
# Array processing with dramatic speedups
large_array = np.random.rand(50000, 20)
# Traditional pandas backend
pandas_df = dw.wrangle(large_array, backend='pandas')
# High-performance Polars backend (2-100x faster!)
polars_df = dw.wrangle(large_array, backend='polars')
# Set global backend preference
from datawrangler.core.configurator import set_dataframe_backend
set_dataframe_backend('polars') # All operations now use Polars
# Text processing also benefits from Polars
fast_text_embeddings = dw.wrangle(text, backend='polars')
The data-wrangler package also provides powerful decorators that can modify existing functions to support new
datatypes. Just write your function as though its inputs are guaranteed to be Pandas DataFrames, and decorate it with
datawrangler.decorate.funnel to enable support for other datatypes without any new code:
image_url = 'https://raw.githubusercontent.com/ContextLab/data-wrangler/main/tests/resources/wrangler.jpg'
image = dw.io.load(image_url)
# define your function and decorate it with "funnel"
@dw.decorate.funnel
def binarize(x):
return x > np.mean(x.values)
binarized_image = binarize(image) # rgb channels will be horizontally concatenated to create a 2D DataFrame
Supported data formats
One package can’t accommodate every foreseeable format or input source, but data-wrangler provides a framework for adding support for new datatypes in a straightforward way. Essentially, adding support for a new data type entails writing two functions:
An
is_<datatype>function, which should returnTrueif an object is compatible with the given datatype (or format), andFalseotherwiseA
wrangle_<datatype>function, which should take in an object of the given type or format and return apandasorPolarsDataFramewith numerical entries
Currently supported datatypes are limited to:
array-like objects (including images)
DataFrame-like orSeries-like objects (pandas and Polars)text data (text is embedded using natural language processing models)
or lists of mixtures of the above.
Backend Support: All operations support both pandas (default) and Polars (high-performance) backends. Choose the backend that best fits your performance requirements and workflow preferences.
Missing observations (e.g., nans, empty strings, etc.) may be filled in using imputation and/or interpolation.